



【摘要】在当前大数据和人工智能时代,以文本为代表的非结构化数据引起了学者们的广泛关注,而这其中文本数据在社会科学尤其在金融研究中发挥着越来越重要的作用。文本分析通过研究文本的情感情绪、政策不确定性、语义相似性等非传统主题正创造着新的金融研究范式。论文聚焦于文本分析在金融研究中的应用这一主题,通过梳理国内外相关文献,首先对文本数据在金融研究中的使用流程与范式进行了总结,详细描述了金融文本的获取方法、金融文本的处理方式、金融文本的表示模型以及金融文本指标的构建这四个关键流程;之后论文结合大语言模型盛行的背景重点分析了大语言模型在金融研究中的潜在应用,并探讨了大语言模型可能带来的风险和挑战,如数据隐私、模型偏见等问题;最后论文对文本分析在金融研究中的应用进行了总结,反思了当前学术界对文本分析的批判,并对大语言模型在金融研究中的使用进行了展望。
「关键词」文本分析;金融研究;非结构化大数据;深度学习;大语言模型
01 引言
21世纪以来,互联网逐渐深入千家万户,社交媒体、新闻网站、电子商务等新兴网络平台正爆炸性地创造着海量的数据。数据的广度、深度不断得到丰富和完善,更新速度不断变快,结构复杂度也持续增加(黄恒君等,2017)。在当前大数据和人工智能时代,各种优秀的计算机算法如雨后春笋般涌现出来,非结构化大数据也成为计算机可以处理和分析的数据,并被广泛应用于非传统领域的金融研究之中(Loughran & Mcdonald,2016)。在金融领域,虽然图片、音频和视频等非结构化数据并未被规范化、模式化的广泛应用到研究分析过程中,但文本数据目前已被大量运用到金融问题的解释和实证分析之中,沈艳等(2019)、马长峰等(2020)、姚加权等(2020)也对文本挖掘及分析技术在经济金融中的应用有了细致的综述,这也表现了当前文本分析正处于欣欣向荣的时刻。本文在前人文献的基础上从文本分析及其研究主题出发对文本分析技术在金融研究中的应用范式进行归纳总结,从技术和应用两个方面入手对金融文本分析的全流程进行了较为细致的综述,深入探讨文本分析的技术应用细节以及在具体金融问题上的应用效果,并引入介绍最新的大语言模型技术,分析了其可能存在的金融应用范式及风险挑战,关注了文本分析技术的局限性和未来研究方向。
02 文本分析及研究主题
文本分析指运用人工理解或技术手段对收集的文本数据进行表示、处理和建模,并以此为基础来获取有用的分析或观点。传统的文本分析有非常久远的历史起源,早在14世纪,多米尼加修道士会就为拉丁语版本的《圣经》制作了常用短语的索引。随着计算机技术的不断发展,语言学与计算机科学相融合,产生了一门新的学科,即自然语言处理(Natural Language Processing,NLP),其主要研究任务包括了词性标注、命名实体识别、机器翻译、情感分析、文本摘要、文本分类等内容。Markov早在1913年就对普希金的诗歌小说《尤金·奥涅金》的语言进行概率化建模并分析证明了其文本存在某些潜在可建模的统计特性;Shannon则尝试建立语言的统计模型并使用该模型根据统计规则去生成文本,这都被视作是传统NLP的最初起源。Werbos提出利用反向传播算法来训练多层感知机,从而解决了单层感知机无法拟合简单异或函数的问题,神经网络(Neural Network,NN)开始迅猛发展,此后,基于神经网络的NLP才开始替代传统NLP成为研究热点(陈德光等,2021)。
文本分析在金融研究中的应用也被称为金融文本分析,Das & Chen(2007)首次将文本分析技术运用到金融领域的社交媒体分析之中,该文使用雅虎股票论坛中的短文本数据对网民关于Amazon股票的情感进行了刻画;之后,Blankespoor et al.(2014)发现了使用Twitter进行信息交流的科技公司在股价表现上具有更大的异常波动和更小的异常买卖价差;金秀等(2018)则利用新浪财经股吧数据构建了投资者情绪指数,并发现投资者情绪与上证指数收益存在长短期效应,这些都是国内外学者利用社交媒体评论进行金融领域相关研究的案例。除此之外,利用金融文本分析技术还可以使用报纸媒体、网络新闻、上市公司年报、政府政策等文本数据进行企业经营管理行为、金融市场风险收益分析、市场预测以及政策不确定性等主题的研究(汪昌云、武佳薇,2015;Azar & Lo,2016;Baker et al.,2016;王靖一、黄益平,2018;洪永淼等,2023)。金融文本分析的灵活性与创新性给当前金融经济分析带来了新的充足数据来源,构建了新的金融研究分析范式,促使金融研究从结构化数据分析迈向非结构化文本数据分析的新阶段。
金融文本分析的完整流程(见图1)可以概括为四个部分:金融文本的获取、金融文本的处理、金融文本的表示以及金融文本指标的构建。以下将从这四个流程以及大语言模型的相关问题回顾国内外文献并进行总结和综述。
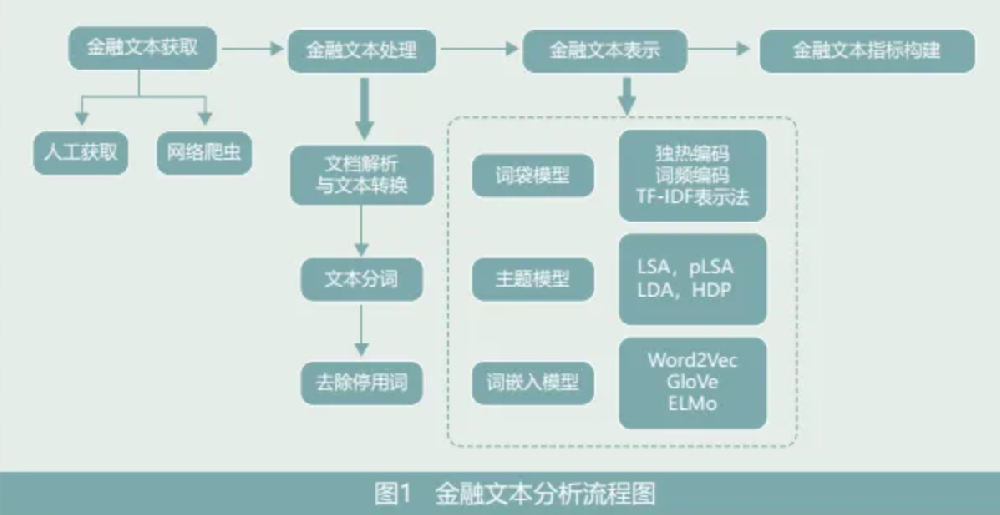
03金融文本的处理与表示
金融文本语料即为可以在金融研究中利用和发挥作用的文字资料。面对早期文本数据量有限的情况,学者基本都是使用人工的方式进行文本的收集和整理。随着互联网时代的到来,每一个网络用户都是信息的生产者,网络上也因此产生了海量的文本信息,使用人工的方式获取金融文本语料显得力不从心。
从使用工具和方法上看,金融文本的获取方式可以分为两类:一是人工获取。即以人工的方式去获取满足需求的文本数据,这种方式需要耗费较多的时间和人力,一般使用在获取文本内容较少并且文本来源较为杂乱、规律性不强的情形。二是网络爬虫。网络爬虫是一种根据需求自动下载网页并进行分析、提取的计算机程序。对于获取的文本量较大,或者来源网页的规律性较强的情形,目前的主流方案是首先人工筛选、分析、确定所需爬取网页的URL,然后编写网络爬虫来爬取所需要的网页文件,并从网页文件中解析、获取、整理文本数据(Loughran & Mcdonald,2014;王靖一、黄益平,2018)。应用网络爬虫大大减少了文本获取行为中的人工工作量,降低了人工收集的出错率,提高了金融文本大数据的获取效率,但在使用爬虫技术时应注意遵循技术中立的原则,避免出现技术恶意使用行为产生的法律风险。
(一)金融文本的处理
利用网络爬虫获取的数据并不是一个统一格式的文本数据,而是类型多样、处理方式各异的数据,一般常见的有HTML文档、PDF文档、Word文档等。对于这些数据,需要经过文档解析与文本转换、文本分词和去除停用词这三个步骤。
1.文档解析与文本转换
在大数据信息时代,无论是政府机关还是公司企业,往往都会以电子文档的形式存储、公布相关信息,以方便读者阅读和内部整理存档。但面对格式多样的数据源文件,计算机并不能进行笼统的自动处理。文档解析与文本转换的意义就在于从不同格式的源文件中解析出文本信息并提取其中有用的文字。通过网络爬虫爬取的源文件一般是HTML文档、PDF文档和Word文档。
HTML文档作为网页源代码,通过一系列标签的形式将文字、图片、表格等信息组合成浏览器通用的显示格式,需要通过正则表达式、Xpath等方式匹配获取所需的文本数据。PDF文档通常由Word或Excel直接转化生成,能够保留原文档的结构信息和文字信息,这种形式的PDF文档可以直接提取里边的文字信息。但有的PDF文档由照片等非解析文件生成,不能直接读取其中的文字信息,这时可以使用光学字符识别(OCR)技术进行文字识别,需要注意的是不同的文字识别方式存在准确率上的差别,需要谨慎选择识别方式(姚加权等,2020)。Word文档较易处理,可以直接从中提取出文字信息。
2.文本分词
分词指的是将一段文本拆分成一系列词语的过程。相较于英文文本中单词与单词之间具有天然的空格分隔,中文文本的分词则需要利用程序和算法将连在一起的句子分割为有间隔的若干词语。中文分词算法主要分为基于词表的分词算法、基于统计模型的分词算法以及基于深度学习的分词算法。目前已有许多优秀的开源模块或者软件使中文分词变得便捷而可靠,如jieba库提供了丰富的分词模式,并支持导入自定义词典以帮助分词结果更加精确;中科院计算所的NLPIR平台包含精准采集、文档格式转换、新词发现、批量分词、语言统计、文本聚类等众多功能,并且在学术界权威性较高,大大降低了文本处理和分析的门槛。
3.去除停用词
哈佛大学语言学家乔治·金斯利·齐夫根据实验统计结果发表了齐夫定律(Zipf’s law),即一个词的词频与它在频率表里的排名r的a次幂成反比。在信息检索领域,停用词被定义为经常出现在文本中但对信息检索没有帮助的、可以消除的词语。根据齐夫定律,无论是在英文还是中文,都会出现一些对句子结构的完整性影响较大,但对语义影响较小的词语,如冠词(the,a,一个)、连词(and,并且)、“的、地、得”等。
目前中文语境下,较为主流且通用的中文停用词词表有百度停用词表、哈尔滨工业大学停用词表以及四川大学机器智能实验室停用词表。官琴等(2017)通过实验对比发现百度停用词表对新闻报道类的文本作用效果更好,哈工大停用词表对文献期刊类文本的作用效果较好,四川大学停用词表更适合邮件文献等类型的文本。
(二)金融文本的表示
文本数据经过分词之后得到从一段文字向一系列词语的有序列表的转换,但对于计算机而言,这些词语序列仍旧需要被转换成计算机可理解的结构(如:向量、树)或者可以处理的0、1数据才能进行下一步的处理。目前学术界常用的文本表示模型主要有:词袋模型(Bag of Words,BoW)、主题模型以及词嵌入模型(Word Embedding)。
词袋模型打破文本中词语的序列顺序限制,仅考虑文档中词语的有无,并根据此进行编码来将文本向量化。根据编码方式的不同,有独热(One-Hot)编码、词频(Term Frequency,TF)编码以及词频-逆文本频率(Term Frequency-Inverse Document Frequency,TF-IDF)表示法。词袋模型的实现和理解都非常简单,不需要复杂的预处理,并且词袋模型计算效率高,能够快速应用于大规模文本数据的处理。然而,词袋模型存在许多固有缺陷:首先,词袋模型忽略了词语的顺序和上下文信息,无法捕捉到文本的语义;此外,词袋模型生成的向量维度非常高,特别是对于大规模语料库,会导致维度灾难问题,对计算资源的需求较高。词袋模型适用于简单的文本分类和聚类任务,如在金融新闻分类中,可以快速应用词袋模型对新闻进行分类,但对于需要理解复杂语义和上下文的任务则不太适用。
主题是特征词的分布概率,主题模型基于词袋模型,是一种生成模型,可以这样来理解:一篇文档中每个词的产生过程是先按照一定的概率选择一个主题,并根据这个主题的主题词多项式的分布生成这个词;也就是说,主题模型把文档从基于词袋模型的向量空间变换到抽象的主题空间中,使得每篇文档可以用主题进行表达,从而达到降维的目的(Vayansky & Kumar,2020)。主题模型一般有潜在语义分析(Latent Semantic Analysis,LSA)、基于LSA思想的概率潜在语义分析(probability Latent Semantic Analysis,pLSA)、潜在狄利克雷分配(Latent Dirichlet Allocation,LDA)、分层狄利克雷过程(Hierarchical Dirichlet Process,HDP)等模型,王靖一、黄益平(2018)在对700GB的和讯网金融科技板块文本数据进行处理时,序列使用了LDA-HDP-LDA的模型组合,文本分析的结果更可靠。
相比不考虑语序的词袋模型,词嵌入模型是考虑词语位置关系的一种模型。通过词嵌入技术,可以将维度为所有词数量的高维空间映射到一个较低维度的连续向量空间中,通过向量之间的欧几里得距离、夹角余弦值等指标可以衡量语义相似度、寻找近义词等。目前,在大型语料库的加持下,词嵌入模型也不断改进、越来越大,常见的词嵌入模型有Word2Vec、GloVe、ELMo等(冉雅璇等,2022)。
04 金融文本的指标构建
在将金融文本应用到金融研究的过程中,还需要根据不同的研究主题构建不同的指标,从而获取到需要的金融研究相关数据。通过总结国内外文献,有以下几个常用的金融文本分析的指标:
(一)金融文本关注度指标
关注度指标衡量了金融文本语料库中某一主题文本的比例,可以采取关键词定位法和主题概率定位法进行指标的构建。关键词定位法侧重以关键词来衡量文本是否属于某一主题,关键在于关键词词典的构建,有时也会考虑关键词词频的影响;而主题概率定位法一般通过主题模型确定文本属于某一主题的概率。
很多指标都是关注度指标的变种或具体应用,比如政策不确定性指数、风险披露程度等。Baker et al.(2016)最初编制经济政策不确定性指数的时候就认为若一篇文章中包含与“不确定性”“经济”和“政策”有关的所有三个类别的术语则该文章为相关报道文章,也对文章数量进行了标准化的处理,并通过相关报道文章占当月文章的比重,构建了经济政策不确定性指数的月度数据。吴武清等(2021)在衡量债券风险披露程度时综合考虑了三个风险披露指标:募集说明书中“风险”一词的出现频数、“风险”一词所在的句子中是否出现否定词汇及其频数和募集说明书“风险因素”章节的字符数,通过这三个风险披露指标构建了债券的风险披露程度。
(二)金融文本情感(情绪)指标
情感指标反映了文本作者对于文本所展示出的情感态度,一般有正面或负面、积极或消极、支持或反对等情感,文本分析中的“语调”也可看做是情绪的一种体现,通过对文本进行情感分析,可以得到文本的情感指标。从本质上看,情感分析可以分为情感认知和极性检测,情感认知的重点是提取一组情感标签,而极性检测更多的是一种面向分类器的方法,具有固定的离散输出,金融文本情感指标的构建多是一种情感的极性检测。目前,文本情感(情绪)指标的构建方式主要有基于统计的方法(又称基于词典的方法)和基于机器学习的方法。
基于统计的方法主要依赖构建好的情感词典展开情感分析工作,核心在于情感倾向词典的构建,以往经常采用人工筛选的方式,将具有明显情感倾向的词语收集起来制作成情感词典,词典的质量直接关系到文本情感分类结果。
在国外相关研究领域,Loughran & Mcdonald(2011)建立的英文情感词典(常被称为LM词典)被广泛应用于学术研究之中,除此之外现在学者大多使用哈佛大学通用调查词典第四版(Harvard IV-4 Dictionary)等词典来构建美联储的沟通情感指数(Schmeling & Wagner,2024)和测度欧洲央行的货币政策立场(Picault & Renault,2017)。在中文语境下,目前已有且公开的中文情感词典有知网(HowNet)情感词典、台湾大学简体中文情感极性词典(NTSUSD)等。很多学者都是在已有情感词典上进行扩展(汪昌云、武佳薇,2015;姜富伟等,2021),比如通过统计词语关联情感倾向性的概率进行情感词的发掘与扩充,使用词向量之间的余弦相似度扩展词典等,这种通过大样本进行情感词典扩充的方法也进一步弥补了因现有词典的不足产生的影响情绪指标有效构建的问题。
机器学习的发展给文本情感分析带来了新的方法论,应用机器学习的方法进行文本分析也受到了诸多学者的青睐(Gentzkow et al.,2019)。传统的机器学习方法将文本情感分析视作是一个二分类问题,主要应用支持向量机(SVM)、K最邻近(KNN)和朴素贝叶斯学习进行分类(Li et al.,2019;Gupta et al.,2020)。对于有监督的机器学习方法,则需要特定领域的数据集,这可以被视为一种限制;若研究人员人工对金融文本自行标注训练集,这会花费时间和人工成本,并且结论的复现性不好、鲁棒性不强(洪永淼等,2023)。
随着深度学习的不断发展,越来越多预训练模型被提出和训练(LeCun et al.,2015)。深度学习的基本思想是使用大量样本训练各种神经网络模型来发现学习文本与情感倾向的潜在联系,通过构建端到端的学习模式,将大部分的特征提取任务黑箱化,尽可能省略人工参与的步骤。众多研究人员以卷积神经网络(CNN)模型、循环神经网络(RNN)模型、注意力机制等模型为基础,开展自然语言处理领域的研究,逐步提出了Transformer、BERT、GPT等优秀的语言模型,并在此基础上进行了更为深入的研究,这些新兴的深度学习模型在情感分析任务上表现出了良好的性能,为情感倾向分析提供了更多的选择。
许多学者利用文本情感(情绪、语调)作为研究变量,分析文本相关的各种情绪对金融市场的影响。Jiang et al.(2019)根据公司财务报表和电话会议中汇总的文本语气构建了经理人的情绪指数,并发现基于文本语气的经理人情绪指数对未来股市回报的预测显著且负面;姜富伟等(2021)利用infobank数据库中的经济新闻数据库构建了媒体文本情绪指标,并发现利用金融情感词典构建的媒体文本情绪对股票市场收益率具有显著的预测能力;姚加权等(2021)则发现年报语调和社交媒体情绪指标对股票市场收益率、波动率、流动性等具有显著的预测效果,并且能够用作预测股票崩盘风险。除此之外,Daas & Puts(2014)则发现荷兰消费者信心变化总是优先于荷兰社交媒体情绪的变化。
(三)金融文本可读性指标
文本可读性,即文本内容是否容易被读者理解、解读和接受,文本的可读性衡量了读者通过阅读准确地重建预期信息的能力。金融文本可读性的内涵是市场参与者从信息披露中获取有效信息的能力,是评估金融文本的信息质量的重要指标(Loughran & Mcdonald,2011)。文本的可读性直接影响读者对文本信息的理解速度以及准确度。可读性越高,文本越容易被理解;反之,可读性越差,则文本越晦涩难懂(Li,2008)。
对于文本可读性的衡量方法有很多种,近几年在金融和会计领域运用得较为普遍的是迷雾指数(Fog Index),它从平均句子长度Average和单词复杂度(如一个句子中复杂词的比例)Complex等方面衡量了阅读者读懂文本信息所需要的最低教育年限,即迷雾指数越高表示文本的可读性越低。上市公司年报(即10-Ks表格)的可读性就可以使用迷雾指数和年报中的字数来衡量,并发现报告期收益较低的公司往往有难以阅读的年度报告(Li,2008)。同样基于句子和单词的阅读效果来衡量文本可读性的指标还有弗莱什易读指数即Flesch-Kincaid等级水平。利用弗莱什易读指数,结合机器学习方法,可以从欧洲央行的演讲等文本中提取主题并系统刻画欧洲央行沟通的清晰度(Ferrara & Angino,2022)。F-K等级水平来源于弗莱什易读指数(Flesch,1948),它的分数可以解释为理解一篇文章所需要的教育年限。分数越高,所用语言的复杂性就越高,文本的可读性也就越低。
(四)金融文本语义相似度指标
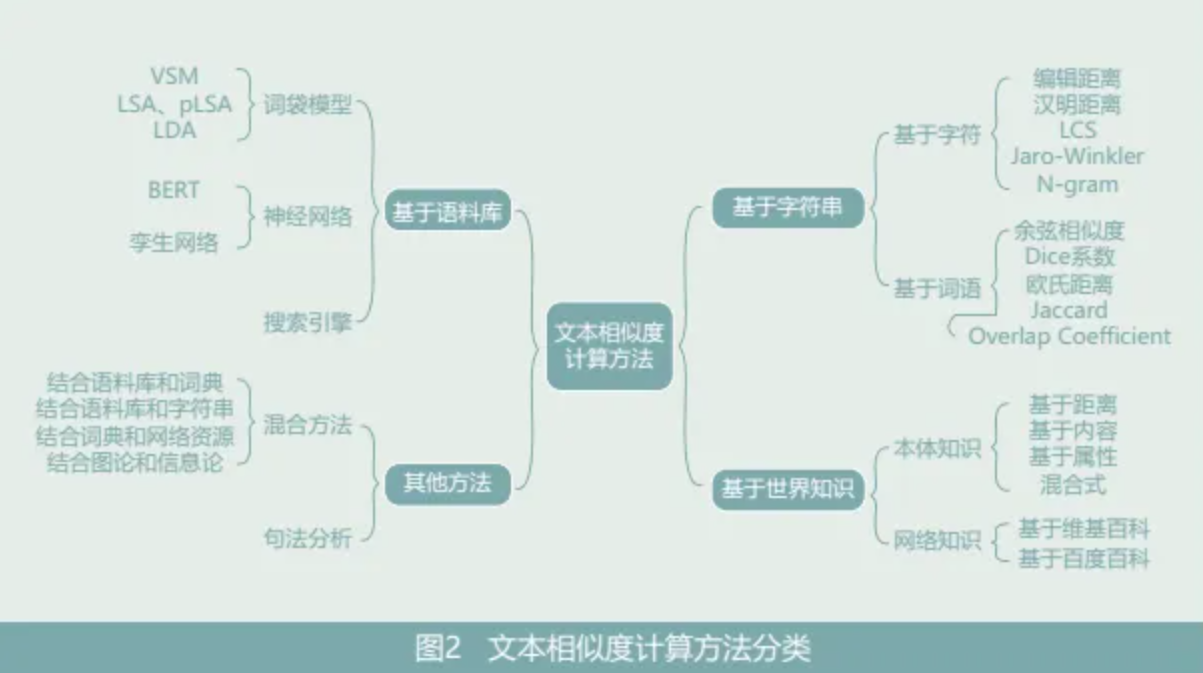
文本的语义相似度指的是不同文本之间在表达的潜在含义和遣词造句等方面的相似程度。在政策文本方面,语义相似度使市场能通过对比前后两期政策文件更好理解政策可能的变化,提高央行沟通的清晰度,熨平市场波动(王博、高青青,2020)。在具体的操作过程中,文本语义相似度的计算方法有多种,根据Gomaa et al.(2013)的分类框架将文本相似度的计算方法梳理如图2所示。
(五)政策不确定性
不确定性指标是近些年通过文本分析构建的使用最为广泛的指标之一。对于政策上的不确定性,利用金融文本分析能够较为及时、准确地反应经济市场主体对于政策不确定性的真实情感状态。Baker et al.(2016)最早利用报纸文本数据对经济政策的不确定性进行测度,并发现在2008年全球金融危机之后,由于企业和家庭对政府未来监管框架、支出、税收、货币政策等的不信任,经济政策的不确定性达到了顶峰,EPU指数也成为了学术界度量经济政策不确定性最常用的指标,并且Baker et al.(2016)分别利用人工阅读进行审计、考虑政治倾向在EPU构建中引起的偏差以及将利用报纸构建的EPU与其他不确定性指标(股票市场的波动率、美联储褐皮书中不确定性和政策不确定性讨论的频率、企业10-K文件中“风险因素”部分的份额等)进行比较进一步说明了通过报纸媒体的文本分析来构建EPU的稳健性和科学性。在这之后,Davis et al.(2019)和Huang & Luk(2020)依照Baker et al.(2016)的EPU指数构建框架,对中国的EPU指数进行了重新构建,选取了不同的报纸并丰富了关键词的筛选,避免了EPU指数受个别媒体报道偏见的影响,并且Huang & Luk(2020)将选择的10份报纸构建的EPU与完整的114份报纸所构建的EPU进行相关性分析,发现二者的相关性为0.96,表明利用两种不同样本进行指数构建之间没有系统性偏差,指数的构建具有一定的稳健性。Arbatli et al.(2017)以日本EPU指数的构建为主要内容,又分类构建了财政、货币、贸易和汇率的政策不确定性指数,认为可信的政策计划和强有力的政策框架可以通过减少政策不确定性对宏观经济表现产生积极影响。
杨赞等(2020)同样在Baker et al.(2016)的基础上,选择慧科数据库中《人民日报》《新快报》《环球时报》等12份中国内地最具影响力的报纸为文本数据来源,聚焦中国内地报纸中关于房地产市场的描述,对关键词词表进行了扩充,建立了中国房地产政策不确定性(Real Estate Policy Uncertainty,REPU)指数。陈英楠等(2022)认为杨赞等(2020)构建的REPU指数仅基于人为经验拓展的关键词词典,难以说明指数构造的准确性,故参考Baker et al.(2016)的报纸文本分析方法,利用人工审计的方法构建了REPU关键词词典,并利用巨灵财经资讯系统中《人民日报》《21世纪经济报道》等6家报纸的文章数据进行REPU的构建,并在此基础上参考Arbatli et al.(2017)讨论了货币政策、财政政策、宏观审慎政策和行政政策对REPU的贡献度,发现在政府出台调控政策及调控态度、调控工具发生转变时,REPU的上升态势明显,并且货币政策和财政政策对REPU的贡献度一直较高。
05 大语言模型
2022年底,美国人工智能研究公司OpenAI发布基于GPT-3.5的生成式人工智能对话系统ChatGPT,其效果超过了之前的人工智能模型,不仅在世界范围内引发了一股人工智能的热潮,还在学术界和产业界都得到了广泛的关注。Noy & Zhang(2023)通过召集444名受过大学教育的专业人士并设置了对照组和实验组验证了使用ChatGPT对文书类工作的生产力和生产质量都得到了提高。ChatGPT能取得如此大的成果,在模型上有以下特点(Zhao et al.,2023):第一,能够理解并学习用户输入的文字信息,并依据对话上下文环境回答问题;第二,训练数据巨大,模型参数一般以百亿量级计数,因此这类模型也被称为大语言模型(Large Language Model,LLM);第三,利用基于人类反馈的强化学习(Reinforcement Learning with Human Feedback,RLHF),让人工智能生成的内容符合人类的价值观(Christiano et al.,2017),这也是避免人工智能产生道德问题的手段;第四,在解决复杂问题时显现出了小模型所没有的“涌现能力”。
ChatGPT的成功也让人们看到了大语言模型在金融领域广泛使用的可能,但与此同时也蕴含着潜在的风险和挑战。
(一)大语言模型在金融领域的应用
大语言模型作为生成式的模型,可以被认为是一种通用式技术,而通用技术的特点是随着时间的推移和技术的普遍应用,这种技术可以推动产业的变革和生产力的解放(例如蒸汽机、内燃机等)。Bommasani et al.(2021)在文章的“经济”章节对大语言模型在经济方面的影响做了简短的评述,指出大语言模型对生产效率、收入分配不平等和所有权集中等方面有重大影响。郑世林等(2023)分析了ChatGPT在经济等多个领域的机遇和挑战,认为ChatGPT作为一种人工智能技术,对不同技能水平劳动者的影响不同,加速了人工智能对人类常规工作的替代,促进了一些传统产业的转型,但也给经济社会带来了信息泄露等安全问题。
在金融业中,大语言模型有潜力代替人力去完成一些重复性的、模式化的工作,从而有效解放金融从业者的生产力,使金融从业者更有时间和精力投入到更具有创造性的金融活动之中。2023年3月,全球最大的金融信息服务商彭博社宣布其训练了第一个金融领域的大语言模型BloombergGPT(Wu et al.,2023)。BloombergGPT参数规模20B,使用了彭博社自建的363B token的金融数据集和345B token的通用数据集,并基于BLOOM模型进行训练,之后Wu et al.(2023)对BloombergGPT在金融中最常考虑的NLP任务进行测试,发现BloombergGPT在绝大部分任务中都远优于BLOOM等通用大语言模型,这也说明了特定领域的大语言模型可以表现出在该领域更优的效果和能力。
在金融研究领域,大语言模型可以有效降低使用者的技术门槛,从原来“会技术、懂模型”到现在“会调用API”,通过API调用即可接入模型进行使用,文本分词、去除停用词、情感分析、语义相似度等任务都可以通过这种方式直接完成。Lopez-Lira & Tang(2023)对ChatGPT等大语言模型是否能够预测股票市场做了研究,通过利用ChatGPT对新闻标题进行情感分析来预测股市回报,最终发现ChatGPT相对于传统情感分析方法具有一定的优势。刘起贵、贲圣林(2023)认为ChatGPT在金融分析、资产分配、量化投资以及风险控制上有潜在的应用场景,可以推动金融行业的变革。但需要注意的是,大语言模型本质上仍然是一个语言模型,对于以上常规的金融相关NLP任务可以实现很好的效果,但像直接进行股票推荐等任务存在“胡言乱语”的现象,可能需要大语言模型相关技术的发展才可实现较好的突破,同时应该关注到深度学习算法目前仍存在“算法黑箱”的问题,解决深度学习的可解释性问题也是实现其更加安全、广泛应用的驱动力之一。
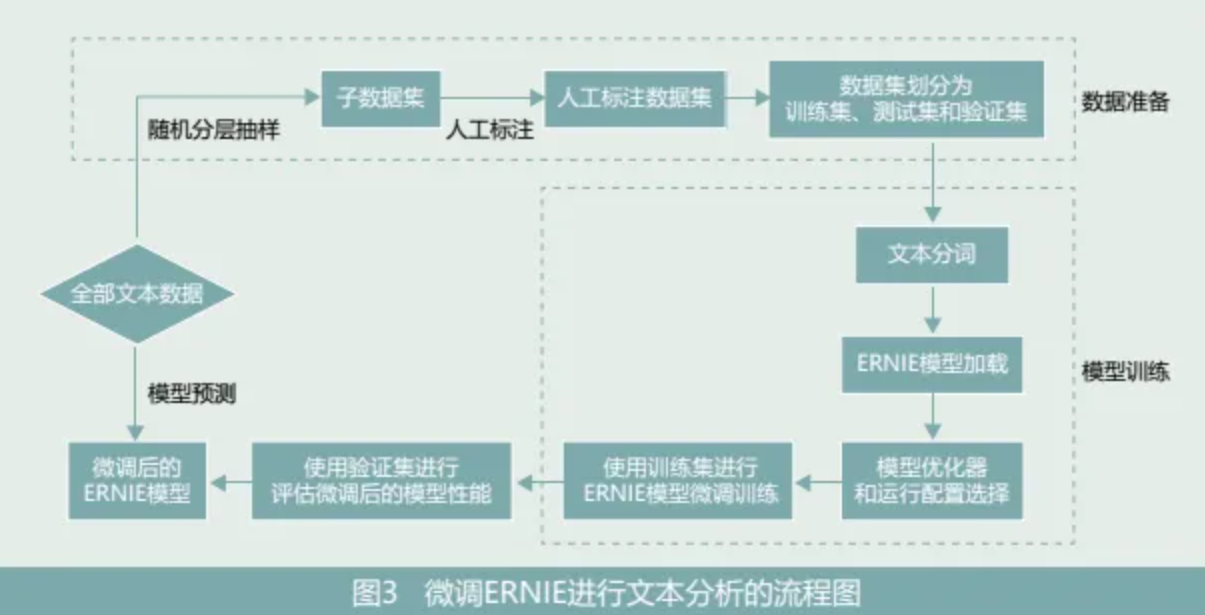
具体来看,将LLM应用到金融研究之中依旧可以遵循上述的金融文本分析的范式。首先,金融文本的获取和处理可以利用LLM与大模型爬虫工具进行网页内容的爬取,多模态大模型优秀的识别能力也可以直接将网页中图片的文字或PDF文档直接转换成文本,并且根据指令LLM可以准确的完成文本分词、去除停用词等基本操作,确保文本处理的准确性;其次,选择合适的大语言模型(如Llama3、BERT等)并进行模型微调是关键一步,通过使用金融领域的特定数据进行模型微调,可以增强模型对金融文本的理解和处理能力,金星晔等(2024)利用公司年报文本把每一句作为一个最小判断单元对百度大模型ERNIE进行微调,从而更好地完成对企业数字化转型的测度,微调ERNIE进行文本分析的流程如图3;再次,在应用场景设计中,可以针对具体的任务如情感分析、市场预测、风险评估和政策分析等,定义每个应用场景的输入和输出,并确定评估标准(例如,在情感分析中,可以通过分析新闻报道的情感倾向来预测市场情绪变化);最后,通过部署微调后的LLM进行实际数据的处理和分析,并根据实际效果调整模型参数,以达到最佳效果。通过上述LLM的应用框架,结合金融领域的专业知识进行模型微调,就可以充分发挥LLM在金融文本分析中的优势,提升分析的准确性和实用性。
(二)大语言模型可能带来的风险和挑战
如上文所述,在金融领域应用大语言模型带来了巨大的潜力和机遇,但同时也伴随着多种风险和挑战。具体分析这些风险和挑战,并提出相应的风险控制和伦理指导原则,对于确保技术的安全和有效应用至关重要。
首先,数据隐私与安全是大语言模型应用中的一个主要风险。金融数据通常包含大量的敏感信息,如公司财务数据、投资策略和客户个人信息,如果这些数据在处理过程中被泄露或未经授权访问,可能会导致严重的经济和法律后果。为此,必须实施强有力的数据加密和访问控制措施,确保数据在传输和存储过程中的安全,并应遵循数据最小化原则,只收集和使用必要的数据,避免过度数据收集。
其次,模型偏见与公平性问题也是大语言模型应用中的一个重要挑战。大语言模型在训练过程中可能继承训练数据中的偏见,从而在分析和决策中表现出不公平性。例如,在对大语言模型进行微调时,如果微调数据在标注时就已经存在偏误,那利用微调好的大语言模型进行推理与预测时则很容易继承这种偏误从而导致结果不准确。为应对这一挑战,需要在模型训练过程中使用公平性算法,定期评估和纠正模型中的偏见,提高模型的公平性和透明度;此外,还应建立多样化的数据集,确保模型能够反映不同群体和市场的真实情况。
再次,结果可解释性是大语言模型应用中的另一大挑战。大语言模型的复杂性使得其输出结果难以解释,这在金融决策中可能引发信任问题和合规风险。因此,开发可解释的模型和工具,使用户能够理解模型的决策逻辑至关重要。
最后,伦理问题也是大语言模型应用中不可忽视的方面。金融研究应遵循数据使用的伦理原则,尊重隐私和数据主权,避免数据滥用和侵犯个人隐私;并且应确保模型的决策过程和结果不对特定群体造成歧视或其他负面影响。
综上所述,虽然大语言模型在金融领域的应用具有巨大的潜力,但也伴随着数据隐私与安全、模型偏见与公平性、结果可解释性以及伦理问题等多种风险和挑战。通过实施强有力的风险控制措施和伦理指导原则,可以有效地评估和控制这些风险,确保大语言模型在金融领域的安全和有效应用。
06 总结和展望
金融文本分析是近年来金融研究领域应用越来越广泛的技术之一,大大拓宽了金融研究的数据来源。首先,本文梳理了国内外金融文本分析相关的文献,对文本分析的起源及研究主题进行了简要的阐述,提出本文的边际性贡献是对文本分析在金融研究中使用的范式进行总结。以及对大语言模型在金融研究中的应用进行整理与思考;其次,本文对文本数据在金融学术研究中的使用流程进行了介绍和总结,较为详细地描述了金融文本的获取方法、金融文本的处理方式、金融文本的表示模型以及金融文本指标的构建;最后,本文结合大语言模型盛行的背景介绍了大语言模型在金融领域的应用并讨论了其中可能存在的风险和挑战。
然而针对目前文本分析技术在金融学术研究领域的广泛应用,有学者对其中的滥用提出了批判,重点提到了文本分析技术在指标构建中存在的逻辑问题和可能存在的测量误差与稳健性等问题。对于那些依赖关键词频率或特定词汇出现次数进行测算的方法,研究人员假设词汇的出现频率直接与研究主题的重要性或程度成正比,但实际情况可能远比这复杂,就导致文本分析技术可能会忽略实际上下文中词汇的使用意义和背后的深层次逻辑。并且关键词的选择、词库的构建以及分析模型的设定都可能引入误差,从而影响结果的稳健性,对于关键词快速更迭和语境多样性可能导致对相同文本的分析结果在不同时间点或使用不同词库时有显著差异。
随着技术的发展和成熟,大语言模型强大的文本理解与分析能力使得文本分析在金融研究中的应用有同大语言模型相结合的趋势和动力,但本文认为针对未来金融文本分析的发展趋势,有以下几个方面可以进行深入讨论和研究:
第一,建立统一的金融文本数据库,丰富金融文本数据来源,提高金融文本数据开源水平。在金融文本分析过程中,原始的金融文本数据一般需要研究人员自己进行搜索挖掘,而不同的主题下可能需要的是相同的文本数据,重复的工作明显不利于整体科研水平的提高。在大语言模型训练过程中,诞生了很多开源的公共数据训练集,主要有:拥有广泛主题的书籍数据库BookCorpus,最大的开源网络爬虫数据库CommonCrawl和基于CommonCrawl的过滤数据集C4、CC-Stories、CC-News、RealNews,基于社交媒体Reddit的文本数据集PushShift.io,维基百科数据集等,这些大规模语料数据库在大语言模型训练过程中起到了极大的促进作用。建立统一的金融文本数据库,聚合各类金融相关文本,并通过开源的方式供研究人员使用,同样也可以提高金融文本分析在金融研究领域的应用水平,这是一件极其有意义但任重道远的事情。
第二,缩短从计算机文本分析技术到金融学术研究之间的时间周期。在当前自然语言处理领域,工程远远走在了科学的前边;但在金融文本分析领域,往往还是在使用一些较为成熟、稳定的技术,这虽然一方面反映了金融研究学者严谨认真的性格,但也有一种不愿打破原有研究范式的惰性。比如在金融文本的表示中,大部分学者使用Word2Vec词嵌入模型将分词结果向量化,但很少有学者使用GloVe、ELMo等词嵌入模型,也很少有文章比较几种词嵌入模型在处理金融文本分析任务中的效果。缩短从计算机文本分析技术到金融学术研究之间的时间周期,合理利用好文本分析新技术,使金融学术研究也能享受到科技发展的红利。
第三,尝试将大语言模型应用到金融文本分析中,加速金融文本分析与大语言模型的融合。大语言模型基于海量的文本数据进行训练,比如GPT-3(175B)在包含300B词元的混合数据集上进行训练、LLaMA(65B)的训练数据集有1.4T词元,这些大语言模型在处理金融文本时有着在训练数据上的天然优势。尝试将大语言模型应用到金融文本分析,比如文本分词、主题分类、情感分析等任务中,可以充分利用大语言模型的优势解决金融研究中的难题,金融文本分析与大语言模型的融合也可能是今后该领域的发展趋势之一。
第四,训练便于应用到金融学术领域的大语言模型。目前除BloomBergGPT以外几乎没有以金融行业文本数据作为训练数据的大语言模型,而BloomBergGPT由于彭博社商业数据隐私性和商业机密等原因不会对外发布,使用金融文本数据训练便于应用到金融学术领域的大语言模型就成了学术研究的基础设施建设。目前国内学术和工业界给出了“开源模型+训练数据”的施行方案,对于金融领域的大语言模型,可以使用开源模型GLM或LLaMA作为基础模型架构,使用收集到的金融文本数据作为训练数据对模型进行训练。
第五,警惕大语言模型在金融学术研究中可能产生的风险。当前大语言模型仍旧是一个算法黑箱的产物,人类还不能很好的解释大语言模型的算法原理和控制机制,这容易产生大语言模型在某种意义上的失控。郑世林等(2023)提到在学术中过度依赖ChatGPT容易产生抄袭、欺诈等风险,也产生了更多新的学术伦理问题,容易产生价值观的扭曲、偏见和渗透问题。除此之外,大语言模型面临的数据隐私与安全、模型偏见与公平性问题、合规性与法律风险等问题依然是困扰金融学术界和产业界能否更加深入地利用大语言模型的障碍。
参考文献略
原文载于《农村金融研究》2024年第11期
(作者尹振涛系中国社会科学院金融研究所金融科技研究室主任、研究员,王振系中国社会科学院大学应用经济学院博士研究生)